
前言
在当今云原生和分布式系统时代,保障系统的高可用性已成为每个技术团队的核心职责。我们不仅要构建具备容错能力的高可用架构,也需要建立完善的健康感知体系,确保能够及时发现并处理各类潜在问题。
监控、拨测与巡检作为系统可用性健康感知的"三剑客",各自承担着不同但互补的职责:监控通过实时指标采集自动化发现已知问题;拨测模拟用户行为黑盒检测业务可用性;巡检则主动排查系统潜在风险,发掘未知问题。然而,仅仅部署这些技术手段还不够,只有将它们有机整合到流程运营管理中,形成完整的闭环管理体系,才能真正发挥其价值。
本文将深入探讨如何在流程运营层面实现三剑客的协同工作,通过建立有效的正向职责驱动快速处置、反向督办持续优化策略,构建起一套完整的系统可用性保障体系。我们将描述在任意事件发生下,流程如何驱动不同团队或组织协同工作。
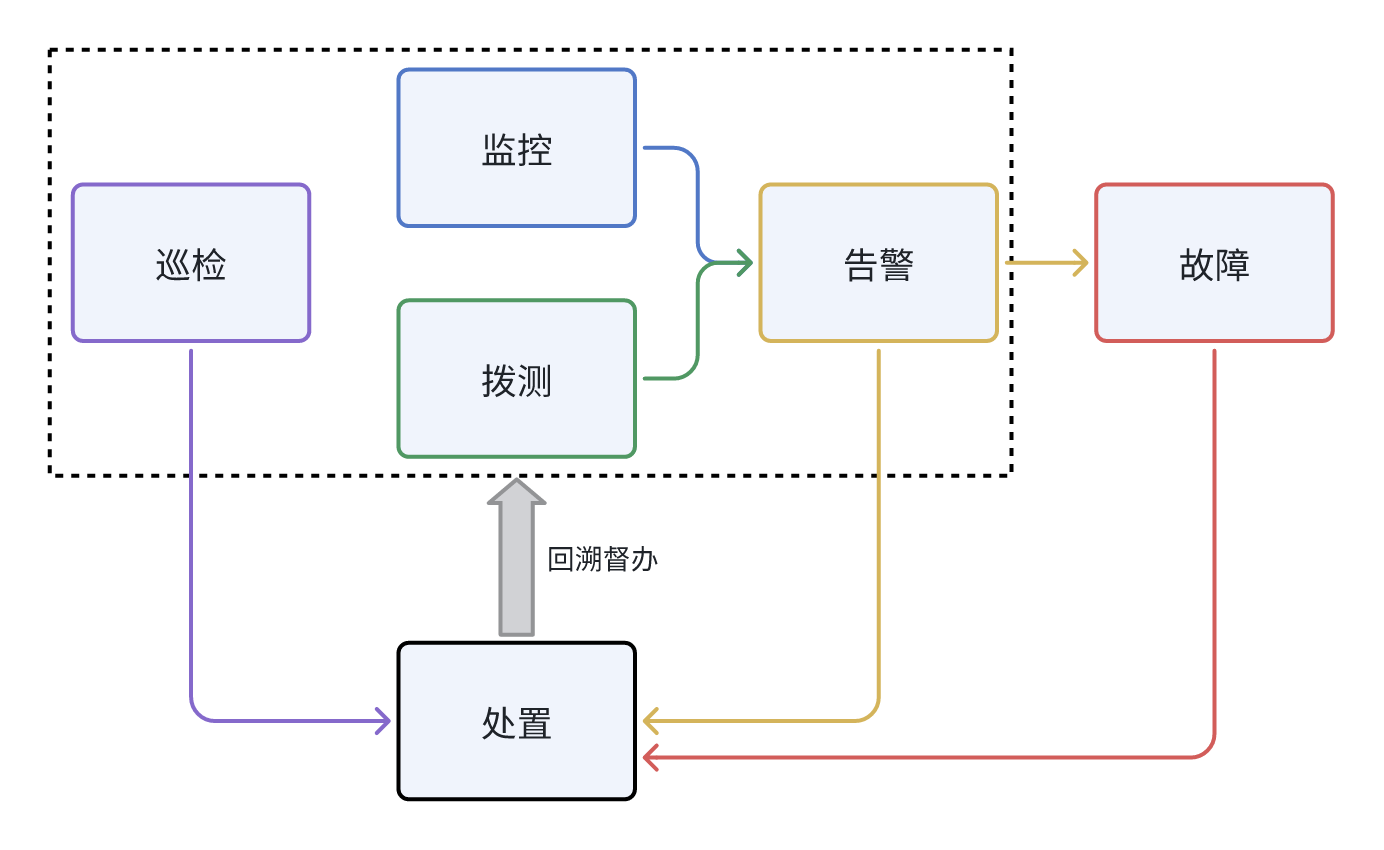
关键词:健康感知 巡检 拨测 监控 组合拳 闭环
正向传播:责任链
在系统可用性保障流程中,正向传播定义了信息和服务的单向流动,其核心思想是建立一套清晰的、仅对直接依赖方负责的责任链。这套机制旨在消除跨环节的模糊责任,确保每个环节的维护者只对自己提供的服务质量负责。
核心原则:近端责任制
责任链模型遵循"近端责任制":每个流程节点(如监控、告警、处置)仅且只对其紧密连接的下游节点提供服务承诺。
- 上游职责:确保输出(服务、数据、事件)的准确性、完整性和及时性。
- 下游职责:确保正确接收上游的输出,并在此基础上执行自身的逻辑,向更下游的节点传递。
如果最终结果出现偏差,责任追溯应向上游倒查,直到找到第一个未能履行服务承诺的环节,该环节即承担主要责任。
职责分配
正向传播的链条主要包含以下关键环节及其责任边界:
监控与拨测 (Monitoring & Probing)
- 对内职责 (向上游系统):无,它们是故障发现的起点。
- 对外职责 (向下游告警):确保能及时、准确地生成反映系统状态或异常的事件流(Event Stream)。
- 责任边界:它们的责任仅限于事件的"生成"。如果系统已发生故障,但监控或拨测的逻辑或配置缺陷导致事件未生成或误判,则主要责任人是监控/拨测的维护团队。
告警 (Alerting)
- 对内职责 (向上游监控/拨测):确保能正确接收、解析和处理来自上游的事件流。
- 对外职责 (向下游处置):确保能将上游接收到的事件,根据预设的规则转化为可行动的通知(Actionable Notification),并送达正确的处置人员。
- 责任边界:告警系统只负责事件的"传播"和"分派"。
- 如果收到了事件,但因告警配置错误、通知渠道故障(如邮件或短信服务不可用)而未能通知到人,则主要责任在告警维护团队。
- 如果未收到上游事件(即监控/拨测环节失败),即使处置滞后,告警维护团队也无直接责任。
处置 (Handling/Resolution)
- 对内职责 (向上游告警/巡检/故障):确保能及时、有效地接收来自告警的通知、来自巡检的发现,以及来自用户的故障报告(故障的直接输入)。
- 对外职责 (对系统恢复):承担最终的恢复和止损责任。
- 责任边界:处置团队的责任始于接收到明确的输入信号。如果信号已到达,但处置人员未能及时响应、未能正确操作或未能有效恢复系统,则责任在处置团队。如果输入信号(告警或巡检发现)缺失,处置团队对初期发现滞后不负主要责任。
责任链的价值
通过严格界定正向传播的责任链,可以带来以下益处:
- 清晰的归责机制 (Clear Accountability): 在故障复盘(RCA)时,可以迅速定位是"发现问题"的流程失败,还是"处理问题"的流程失败。
- 专业的焦点投入 (Focused Expertise): 每个团队只需将精力投入到提高自身环节的SLA(服务等级协议)上,例如监控团队只需关注事件的覆盖率和准确率,告警团队只需关注通知的送达率和时效性。
- 减少推诿 (Reduce Blame Shifting): 因为责任边界清晰,可以有效避免不同团队之间在故障发生时互相推诿。
反向传播:优化督办
监控和拨测是健康感知的事件源,但是如果故障直接发生,而监控、拨测都无感知,则告警、处置团队也就没有责任,存在运营漏洞,故障直接由用户反馈(投诉)。如果是完全未知也从未发生的故障,那么此情况发生可以说得过去,但类似故障第二次发生则就非常不应该了,反向的优化督办机制则有效保证了不能在同一个故障上跌倒两次,"吃一堑、长一智"。
如果说"正向传播:责任链"解决了故障发生时的归责问题,那么"反向传播:优化督办"则解决了故障发生后的改进问题。机制核心在于,利用故障的处置结果,向流程上游发送优化督办工单,从而形成一个驱动可用性不断提升的闭环。
核心机制:处置驱动的督办单
处置(Handling/Resolution)团队作为整个可用性保障流程的终点和复盘中心,对已发生的故障承担恢复和止损的责任。在故障解决后,处置团队会分析故障发现、告警、定位等各个环节中的不足,并以优化督办工单的形式,将优化需求反向传递给上游环节。
被督办环节包括:
- 监控与拨测:督办增加新的监控指标、优化拨测频率或路径,以期更早、更准确地发现同类故障。
- 告警:督办优化告警规则、通知路由、收敛策略,以确保告警能及时送达给正确的人员。
- 巡检:督办在日常巡检中增加检查项,弥补自动化监控的不足。
问责博弈:双重责任锁定机制
督办机制最巧妙之处在于其内嵌的"双重责任锁定"逻辑,它利用处置团队是否对督办结果进行验收作为责任转移的依据,巧妙地激发所有团队的行动力。
场景一:处置团队介入验收(回执被认可)
- 流程:处置团队发送督办单 被督办方执行优化 处置团队检查并认可回执(认可了改进机制)。
- 责任锁定:如果被督办方不履行职责,则直接考核处罚;如果未来再次发生相同或类似的故障,责任将转回处置团队。
- 博弈结果:这激励了处置团队必须进行彻底和严格的验收,因为一旦验收通过,他们就对改进方案的有效性负连带责任。
场景二:处置团队仅发出督办(未检查结果)
- 流程:处置团队发送督办单 被督办方执行优化 处置团队未检查/未明确认可。
- 责任锁定:如果未来再次发生相同或类似的故障,此督办单将成为直接证据,证明被督办方未落实优化方案或落实不到位,因此主要责任将转嫁给被督办方。
- 博弈结果:这迫使被督办团队必须认真对待并彻底执行优化方案。他们不能对督办单置之不理,否则这份未关闭的督办单将成为未来故障中自身"没有作为"的直接证据。
对于场景一和场景二两种策略,作者认为场景二是更合理的,虽然看起来是一种"后果自负"的风险博弈,主要原因有2点:
- 各自安好:处置团队难以对优化结果进行有效验收,在职责划分和专业性上存在壁垒,应各自对自己负责即可。
- 自我管理:如果督办单未落实,那么将会"故障重现",必然追责处罚。该机制激发主动性维护,自己对自己负责,而不是对督办方负责。
运营价值:促进持续改进
这种"以责促优,以优避责"的运营机制,将团队间的关系从简单的服务提供(正向链)升级为互为约束和推动的伙伴关系,从而实现:
- 主动优化 (Proactive Improvement):处置团队为了避免未来自己承担责任,会主动发出督办;被督办团队为了避免未执行督办的直接证据,会主动落实优化。
- 流程自检 (Process Self-Correction):督办单机制迫使所有团队定期审视自身流程的薄弱环节,确保整个可用性闭环是健壮和完善的。
总结:双向流动的可用性引擎
| 方向 | 机制 | 责任界定 | 目标 |
|---|---|---|---|
| 正向 | 责任链 | 近端责任制(前者对后者负责) | 快速确定故障发生时的第一责任人 |
| 反向 | 优化督办 | 双重责任锁定机制 | 推动持续改进,避免同类故障再现 |
系统可用性运营闭环通过正向传播与反向传播的辩证统一,实现了"发现即问责,复盘即改进"的高效运营目标。
正向传播的责任链以"近端责任制"为核心,通过信号分层,明确了监控、告警、处置各环节的服务承诺和问责边界,有效对抗了"狼来了"效应,确保了故障的快速归责。而反向传播的优化督办,则利用督办单的"双重责任锁定机制",通过风险的巧妙转移和问责博弈,激发上游团队主动优化的内生动力。
这种双向机制将团队间的关系从简单的服务提供者升级为互相制衡、共同追求可用性目标的核心伙伴,最终确保了系统可用性保障流程的健壮性、效率和可持续性,是构建面向大规模分布式系统的高效可用性运营体系的关键。
参考
本文来自于作者的实际工作经验与思考,并与 Gemini 3 进行了讨论互动。